
Picture by Writer
Massive Language Fashions have revolutionized the Pure Language Processing discipline, providing unprecedented capabilities in duties like language translation, sentiment evaluation, and textual content technology.
Nevertheless, coaching such fashions is each time-consuming and costly. Because of this fine-tuning has develop into an important step for tailoring these superior algorithms to particular duties or domains.
Simply to verify we’re on the identical web page, we have to recall two ideas:
- Pre-trained language fashions
- Fantastic-tuning
So let’s break down these two ideas.
What’s a Pre-trained Massive Language Mannequin?
LLMs are a particular class of Machine Studying meant to foretell the subsequent phrase in a sequence primarily based on the context offered by the earlier phrases. These fashions are primarily based on the Transformers structure and are educated on in depth textual content knowledge, enabling them to know and generate human-like textual content.
The very best a part of this new know-how is its democratization, as most of those fashions are underneath open-source license or are accessible by APIs at low prices.

Picture by Writer
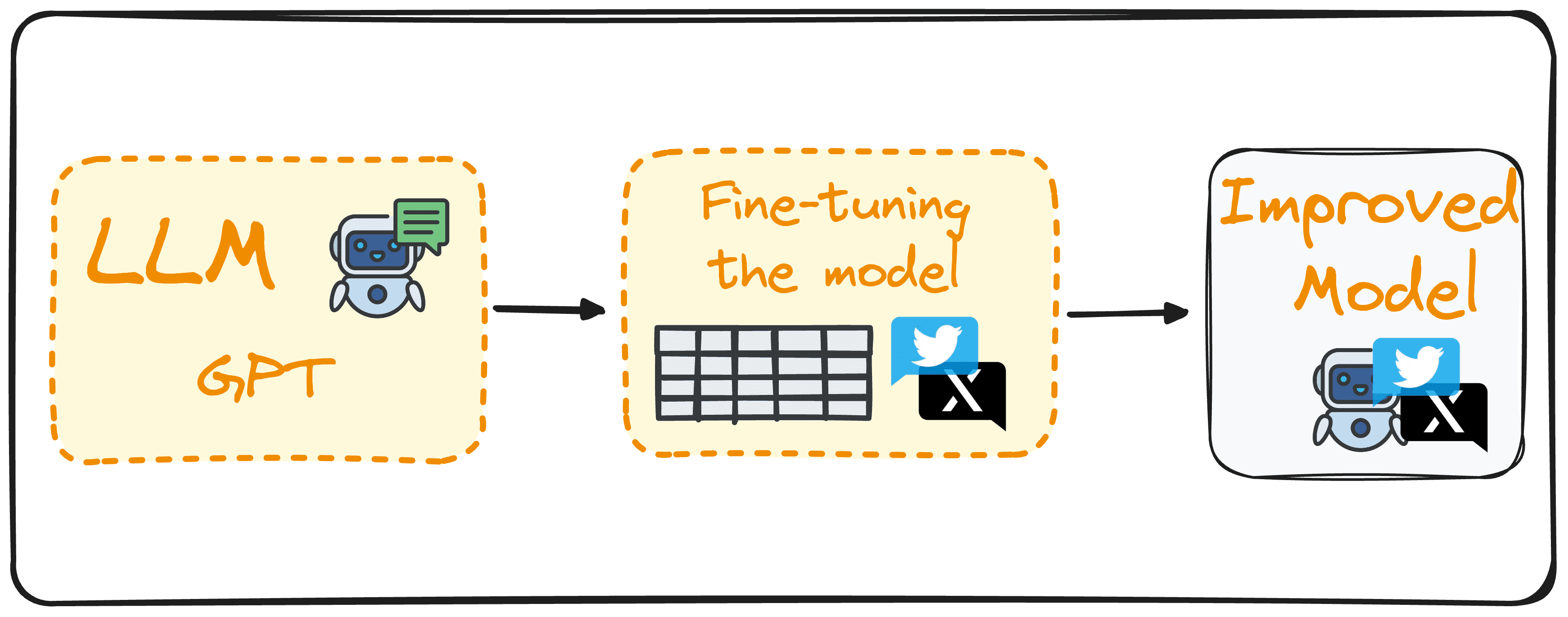
What’s Fantastic-tuning?
Fantastic-tuning includes utilizing a Massive Language Mannequin as a base and additional coaching it with a domain-based dataset to reinforce its efficiency on particular duties.
Let’s take for instance a mannequin to detect sentiment out of tweets. As an alternative of making a brand new mannequin from scratch, we may make the most of the pure language capabilities of GPT-3 and additional practice it with an information set of tweets labeled with their corresponding sentiment.
This could enhance this mannequin in our particular activity of detecting sentiments out of tweets.
This course of reduces computational prices, eliminates the necessity to develop new fashions from scratch and makes them more practical for real-world functions tailor-made to particular wants and targets.

Picture by Writer
So now that we all know the fundamentals, you’ll be able to learn to fine-tune your mannequin following these 7 steps.
Numerous Approaches to Fantastic-tuning
Fantastic-tuning will be applied in numerous methods, every tailor-made to particular targets and focuses.
Supervised Fantastic-tuning
This widespread methodology includes coaching the mannequin on a labeled dataset related to a particular activity, like textual content classification or named entity recognition. For instance, a mannequin might be educated on texts labeled with sentiments for sentiment evaluation duties.
Few-shot Studying
In conditions the place it isn’t possible to collect a big labeled dataset, few-shot studying comes into play. This methodology makes use of just a few examples to offer the mannequin a context of the duty, thus bypassing the necessity for in depth fine-tuning.
Switch Studying
Whereas all fine-tuning is a type of switch studying, this particular class is designed to allow a mannequin to sort out a activity completely different from its preliminary coaching. It makes use of the broad information acquired from a normal dataset and applies it to a extra specialised or associated activity.
Area-specific Fantastic-tuning
This strategy focuses on making ready the mannequin to grasp and generate textual content for a particular business or area. By fine-tuning the mannequin on textual content from a focused area, it positive factors higher context and experience in domain-specific duties. For example, a mannequin could be educated on medical data to tailor a chatbot particularly for a medical software.
Greatest Practices for Efficient Fantastic-tuning
To carry out a profitable fine-tuning, some key practices must be thought of.
Information High quality and Amount
The efficiency of a mannequin throughout fine-tuning drastically is determined by the standard of the dataset used. At all times take into account:
Rubbish in, rubbish out.
Due to this fact, it is essential to make use of clear, related, and adequately massive datasets for coaching.
Hyperparameter Tuning
Fantastic-tuning is an iterative course of that usually requires changes. Experiment with completely different studying charges, batch sizes, and coaching durations to search out the optimum configuration on your mission.
Exact tuning is important to environment friendly studying and adapting to new knowledge, serving to to keep away from overfitting.
Common Analysis
Repeatedly monitor the mannequin’s efficiency all through the coaching course of utilizing a separate validation dataset.
This common analysis helps observe how effectively the mannequin is acting on the supposed activity and checks for any indicators of overfitting. Changes needs to be made primarily based on these evaluations to fine-tune the mannequin’s efficiency successfully.
Navigating Pitfalls in LLM Fantastic-Tuning
This course of can result in unsatisfactory outcomes if sure pitfalls usually are not prevented as effectively:
Overfitting
Coaching the mannequin with a small dataset or present process too many epochs can result in overfitting. This causes the mannequin to carry out effectively on coaching knowledge however poorly on unseen knowledge, and due to this fact, have a low accuracy for real-world functions.
Underfitting
It happens when the coaching is just too transient or the educational charge is about too low, leading to a mannequin that does not be taught the duty successfully. This produces a mannequin that doesn’t know tips on how to carry out our particular objective.
Catastrophic Forgetting
When fine-tuning a mannequin on a particular activity, there is a threat of the mannequin forgetting the broad information it initially had. This phenomenon, often known as catastrophic forgetting, reduces the mannequin’s effectiveness throughout numerous duties, particularly when contemplating pure language expertise.
Information Leakage
Be sure that your coaching and validation datasets are utterly separate to keep away from knowledge leakage. Overlapping datasets can falsely inflate efficiency metrics, giving an inaccurate measure of mannequin effectiveness.
Ultimate Ideas and Future Steps
Beginning the method of fine-tuning massive language fashions presents an enormous alternative to enhance the present state of fashions for particular duties.
By greedy and implementing the detailed ideas, greatest practices, and crucial precautions, you’ll be able to efficiently customise these strong fashions to swimsuit particular necessities, thereby absolutely leveraging their capabilities.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is at present working within the knowledge science discipline utilized to human mobility. He’s a part-time content material creator targeted on knowledge science and know-how. Josep writes on all issues AI, overlaying the appliance of the continued explosion within the discipline.

Samsung Galaxy M34 5G (Midnight Blue,6GB,128GB)|120Hz sAMOLED Display|50MP Triple No Shake Cam|6000 mAh Battery|4 Gen OS Upgrade & 5 Year Security Update|12GB RAM with RAM+|Android 13|Without Charger
₹13,999.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
POCO C65 Matte Black 4GB RAM 128GB ROM
₹6,799.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord Buds 2r True Wireless in Ear Earbuds with Mic, 12.4mm Drivers, Playback:Upto 38hr case,4-Mic Design, IP55 Rating [ Misty Grey ]
₹1,799.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord Buds 2 TWS in Ear Earbuds with Mic,Upto 25dB ANC 12.4mm Dynamic Titanium Drivers, Playback:Upto 36hr case, 4-Mic Design, IP55 Rating, Fast Charging [Thunder Gray]
₹2,499.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Noise Diva Smartwatch with Diamond Cut dial, Glossy Metallic Finish, AMOLED Display, Mesh Metal and Leather Strap Options, 100+ Watch Faces, Female Cycle Tracker Smart Watch for Women (Gold Link)
₹2,999.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹249.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP v236w USB 2.0 64GB Pen Drive,
₹429.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dyazo 6 Angles Adjustable Aluminum Ergonomic Foldable Portable Tabletop Laptop/Desktop Riser Stand Holder Compatible for MacBook, HP, Dell, Lenovo & All Other Notebook (Silver)
₹399.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ZEBRONICS Zeb-Jaguar Wireless Mouse, 2.4GHz with USB Nano Receiver, High Precision Optical Tracking, 4 Buttons, Plug & Play, Ambidextrous, for PC/Mac/Laptop (Black+Grey)
₹299.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ZEBRONICS Zeb-Comfort Wired USB Mouse, 3-Button, 1000 DPI Optical Sensor, Plug & Play, for Windows/Mac, Black
₹99.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)Auto Amazon Links: No products found.