
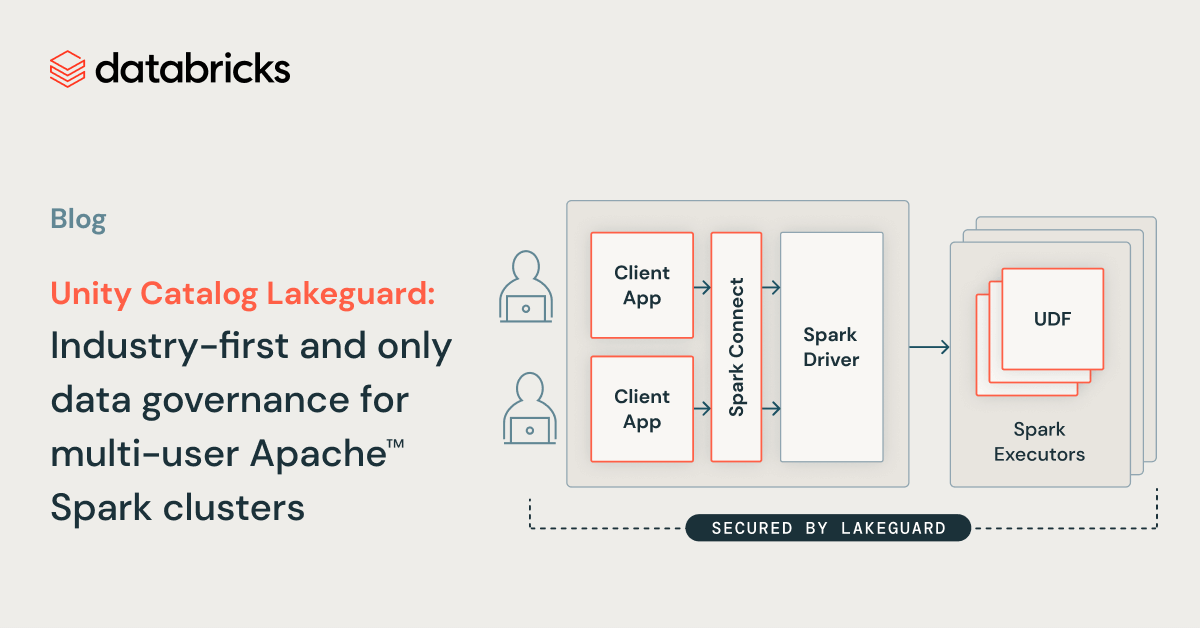
We’re thrilled to announce Unity Catalog Lakeguard, which lets you run Apache Spark™ workloads in SQL, Python, and Scala with full knowledge governance on the Databricks Information Intelligence Platform’s cost-efficient, multi-user compute. To implement governance, historically, you had to make use of single-user clusters, which provides value and operational overhead. With Lakeguard, person code runs in full isolation from another customers’ code and the Spark engine on shared compute, thus implementing knowledge governance at runtime. This lets you securely share clusters throughout your groups, decreasing compute value and minimizing operational toil.
Lakeguard has been an integral a part of Unity Catalog since its introduction: we steadily expanded the capabilities to run arbitrary code on shared clusters, with Python UDFs in DBR 13.1, Scala assist in DBR 13.3 and at last, Scala UDFs with DBR 14.3. Python UDFs in Databricks SQL warehouses are additionally secured by Lakegaurd! With that, Databricks clients can run workloads in SQL, Python and Scala together with UDFs on multi-user compute with full knowledge governance.
On this weblog put up, we give an in depth overview of Unity Catalog’s Lakeguard and the way it enhances Apache Spark™ with knowledge governance.
Lakeguard enforces knowledge governance for Apache Spark™
Apache Spark is the world’s hottest distributed knowledge processing framework. As Spark utilization grows alongside enterprises’ deal with knowledge, so does the necessity for knowledge governance. For instance, a standard use case is to restrict the visibility of knowledge between totally different departments, corresponding to finance and HR, or safe PII knowledge utilizing fine-grained entry controls corresponding to views or column and row-level filters on tables. For Databricks clients, Unity Catalog affords complete governance and lineage for all tables, views, and machine studying fashions on any cloud.
As soon as knowledge governance is outlined in Unity Catalog, governance guidelines must be enforced at runtime. The most important technical problem is that Spark doesn’t provide a mechanism for isolating person code. Totally different customers share the identical execution setting, the Java Digital Machine (JVM), opening up a possible path for leaking knowledge throughout customers. Cloud-hosted Spark companies get round this downside by creating devoted per-user clusters, which carry two main issues: elevated infrastructure prices and elevated administration overhead since directors should outline and handle extra clusters. Moreover, Spark has not been designed with fine-grained entry management in thoughts: when querying a view, Spark “overfetches” recordsdata, i.e fetches all recordsdata of the underlying tables utilized by the view. As a consequence, customers might doubtlessly learn knowledge they haven’t been granted entry to.
At Databricks, we solved this downside with shared clusters utilizing Lakeguard below the hood. Lakeguard transparently enforces knowledge governance on the compute degree, guaranteeing that every person’s code runs in full isolation from another person’s code and the underlying Spark engine. Lakeguard can also be used to isolate Python UDFs within the Databricks SQL warehouse. With that, Databricks is the industry-first and solely platform that helps safe sharing of compute for SQL, Python and Scala workloads with full knowledge governance, together with enforcement of fine-grained entry management utilizing views and column-level & row-level filters.
Lakeguard: Isolating person code with state-of-the-art sandboxing
To implement knowledge governance on the compute degree, we developed our compute structure from a safety mannequin the place customers share a JVM to a mannequin the place every person’s code runs in full isolation from one another and the underlying Spark engine in order that knowledge governance is at all times enforced. We achieved this by isolating all person code from (1) the Spark driver and (2) the Spark executors. The picture under exhibits how within the conventional Spark structure (left) customers’ consumer purposes share a JVM with privileged entry to the underlying machine, whereas with Shared Clusters (proper), all person code is totally remoted utilizing safe containers. With this structure, Databricks securely runs a number of workloads on the identical cluster, providing a collaborative, cost-efficient, and safe answer.
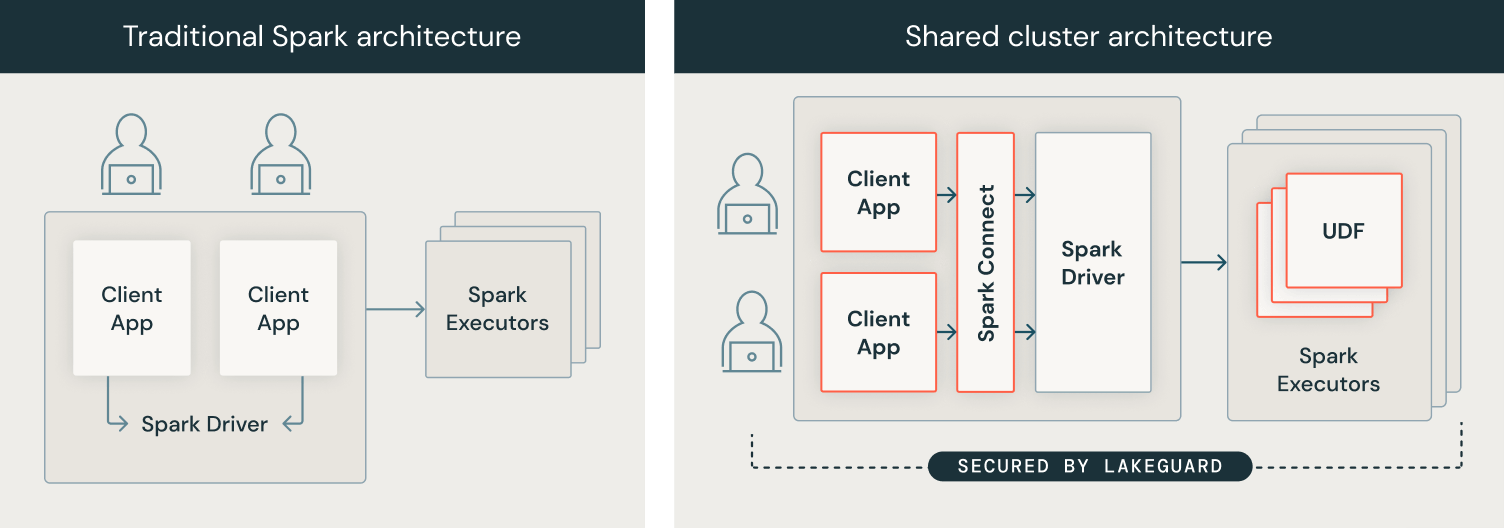
Spark Shopper: Consumer code isolation with Spark Join and sandboxed consumer purposes
To isolate the consumer purposes from the Spark driver, we needed to first decouple the 2 after which isolate the person consumer purposes from one another and the underlying machine, with the objective of introducing a totally trusted and dependable boundary between particular person customers and Spark:
- Spark Join: To attain person code isolation on the consumer facet, we use Spark Join that was open-sourced in Apache Spark 3.4. Spark Join was launched to decouple the consumer software from the driving force in order that they not share the identical JVM or classpath, and will be developed and run independently, main to raised stability, upgradability and enabling distant connectivity. By utilizing this decoupled structure, we are able to implement fine-grained entry management, as “over-fetched” knowledge used to course of queries over views or tables with row-level/column-level filters can not be accessed from the consumer software.
- Sandboxing consumer purposes: As a subsequent step, we enforced that particular person consumer purposes, i.e. person code, couldn’t entry one another’s knowledge or the underlying machine. We did this by constructing a light-weight sandboxed execution setting for consumer purposes utilizing state-of-the-art sandboxing strategies based mostly on containers. As we speak, every consumer software runs in full isolation in its personal container.
Spark Executors: Sandboxed executor isolation for UDFs
Equally to the Spark driver, Spark executors don’t implement isolation of user-defined capabilities (UDF). For instance, a Scala UDF might write arbitrary recordsdata to the file system due to privileged entry to the machine. Analogously to the consumer software, we sandboxed the execution setting on Spark executors to be able to securely run Python and Scala UDFs. We additionally isolate the egress community site visitors from the remainder of the system. Lastly, for customers to have the ability to use their libraries in UDFs, we securely replicate the consumer setting into the UDF sandboxes. In consequence, UDFs on shared clusters run in full isolation, and Lakeguard can also be used for Python UDFs within the Databricks SQL knowledge warehouse.
Save time and value at this time with Unity Catalog and Shared Clusters
We invite you to strive Shared Clusters at this time to collaborate together with your workforce and save value. Lakeguard is an integral part of Unity catalog and has been enabled for all clients utilizing Shared Clusters, Delta Reside Tables (DLT) and Databricks SQL with Unity Catalog.

realme Buds 2 Wired in Ear Earphones with Mic (Black)
₹599.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple iPhone 13 (128GB) - Starlight
₹49,299.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C 5G (Startrail Silver, 4GB RAM, 128GB Storage) | MediaTek Dimensity 6100+ 5G | 90Hz Display
₹10,999.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CP PLUS 2MP Smart Wi-fi CCTV Camera | 360° & Full HD Home Security | Full Color Night Vision | 2-Way Talk | Advanced Motion Tracking | SD Card Support (Upto 256GB) | IR Distance 20Mtr | EZ-P21
₹949.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C (Stardust Black, 6GB RAM, 128GB Storage) | Powered by 4G MediaTek Helio G85 | 90Hz Display | 50MP AI Triple Camera
₹8,699.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell MS116 Wired Optical Mouse, 1000DPI, LED Tracking, Scrolling Wheel, Plug and Play
₹299.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L 1.2M POR-1401 Fast Charging 3A 8 Pin USB Cable with Charge & Sync Function (White)
₹129.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Zebronics-NS1500 Laptop Stand Featuring Foldable Design, Anti-Slip Silicone Rubber Pads, Supports Maximum of 5kgs Weight Tabletop
₹299.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹249.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 101 Wired Optical Mouse with 1200 DPI, Plug & Play, Hi-Optical Tracking, 1.25M Cable Length, 30 Million Click Life(Black)
₹117.00 (as of April 24, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
UnionSine 1TB Ultra Slim Portable External Hard Drive HDD-USB 3.0 for PC, Mac, Laptop, PS4, Xbox one,Xbox 360-Super Fast Transmission-HD-2510(Black)
$46.61 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 4TB External Hard Drive HDD – USB 3.0 for PC, Mac, Xbox, & PlayStation - 1-Year Rescue Service (STGX4000400)
$99.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG SSD T7 Portable External Solid State Drive 1TB, Up to USB 3.2 Gen 2, Reliable Storage for Gaming, Students, Professionals, MU-PC1T0T/AM, Gray
$109.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM750e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$99.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)